With the Hive version 0.14 and above, you can perform the update and delete on the Hive tables. In this post, we are going to see how to perform the update and delete operations in Hive.
But update delete in Hive is not automatic and you will need to enable certain properties to enable ACID operation in Hive.

Update and Delete Operations in Hive
If you haven’t enabled the properties in Hive and try to delete a certain record from the Hive table, then you may get following error-
FAILED: SemanticException [Error 10294]: Attempt to do update or delete using transaction manager that does not support these operations in hive-0.14.0
That means the properties are not enabled in your system to perform the update and delete operations in Hive.
 So, if you are also getting this error, here is the solution to resolve this.
So, if you are also getting this error, here is the solution to resolve this.
Prerequisite to perform Hive CRUD using ACID operations
Here are some perquisites to perform the update and delete operation on Hive tables. These are the minimum requirements for the CRUD operation using the ACID properties in Hive.
- The version of Hive should be minimum 0.14 and above
- File format must be in ORC file format with TBLPROPERTIES(‘transactional’=’true’)
- Table on which you want to perform the update and delete operation must be CLUSTERED BY with some Buckets
- Properties (explained below) must be enabled. You can add these properties in Hive-Site.xml for the global changes or on the command like for the session changes.
If you’re fulfilling these requirements, you can go ahead and perform the update delete in hive.
If your table is not bucketed, again you’ll get the following error:
FAILED: SemanticException [Error 10297]: Attempt to do update or delete on table student2 that does not use an AcidOutputFormat or is not bucketed.
 Properties to enable update and delete operation in Hive
Properties to enable update and delete operation in Hive
Here are some of the properties you need to add in the hive-site.xml file in order to enable the update and delete in Hive tables.
hive.support.concurrency – true hive.enforce.bucketing – true hive.exec.dynamic.partition.mode – nonstrict hive.txn.manager –org.apache.hadoop.hive.ql.lockmgr.DbTxnManager hive.compactor.initiator.on – true hive.compactor.worker.threads – 1
You need to add these parameters to the hive-site.xml file.
Once done, restart the hive services for the changes to take place.
If you are not comfortable making changes in Hive-site.xml, you can do it from command line also. But when you do from the command line, the changes will be valid for that session only.
To enable these CRUD operation properties in Hive from the command line, you can simply run these on the command line like below-
You need to do this for all the properties like below-

Set hive.support.concurrency = true Set hive.enforce.bucketing = true set hive.exec.dynamic.partition.mode = nonstrict set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager set hive.compactor.initiator.on = true set hive.compactor.worker.threads =1
Once done, you are good to perform the update and delete operations on Hive tables.
How to perform the update and delete on Hive tables
By now, we have seen what all need to be done in order to perform the update and delete on Hive tables.
Now, let’s us take an example and show how to do that-
I am creating a normal table in Hive with just 3 columns-
Id Name Location
And load some data in that table as shown below-
hive> create table HiveTest2 (id int, name string, location string) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile; OK Time taken: 0.161 seconds hive> load data local inpath '/home/cloudera/Desktop/file1' into table HiveTest2; Loading data to table default.hivetest2 Table default.hivetest2 stats: [numFiles=1, totalSize=62] OK Time taken: 1.059 seconds
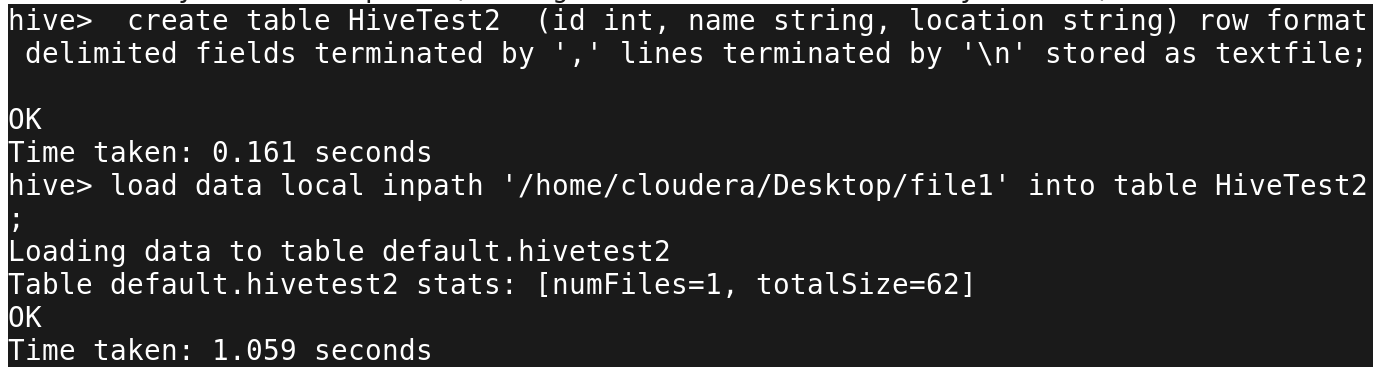 Once done, you need to create the table on which you want to perform the CRUD operations. Make sure the table is bucketed else you won’t be able to perform the update and delete operations.
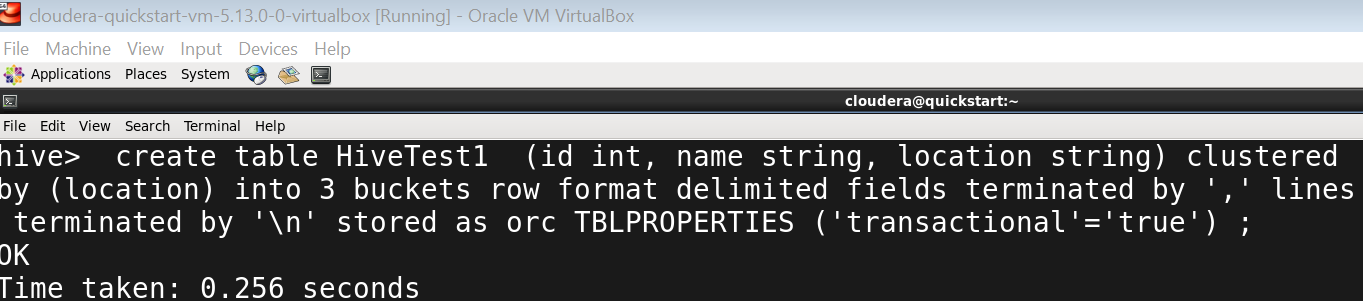
Once done, you need to create the table on which you want to perform the CRUD operations. Make sure the table is bucketed else you won’t be able to perform the update and delete operations.
hive> create table HiveTest1 (id int, name string, location string) clustered by (location) into 3 buckets row format delimited fields terminated by ',' lines terminated by '\n' stored as orc TBLPROPERTIES ('transactional'='true') ;
OK
Time taken: 0.256 seconds
 Now we have the table HiveTest1 on which we will perform the CRUD operations. But before that, we need to add some data in it. For this, we can take the data of our normal table HiveTest2 which we created above and loaded data.
Now we have the table HiveTest1 on which we will perform the CRUD operations. But before that, we need to add some data in it. For this, we can take the data of our normal table HiveTest2 which we created above and loaded data.
hive> insert into HiveTest1 select * from HiveTest2; Query ID = cloudera_20181008035050_bbd1dc4c-1c87-4542-a8e1-1de1621c30bd Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 3 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer= In order to limit the maximum number of reducers: set hive.exec.reducers.max= In order to set a constant number of reducers: set mapreduce.job.reduces= Starting Job = job_1538648439686_0006, Tracking URL = http://quickstart.cloudera:8088/proxy/application_1538648439686_0006/ Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1538648439686_0006 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 3 2018-10-08 03:51:13,006 Stage-1 map = 0%, reduce = 0% 2018-10-08 03:51:36,097 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.25 sec 2018-10-08 03:52:26,578 Stage-1 map = 100%, reduce = 33%, Cumulative CPU 4.89 sec 2018-10-08 03:52:29,650 Stage-1 map = 100%, reduce = 91%, Cumulative CPU 7.35 sec 2018-10-08 03:52:34,307 Stage-1 map = 100%, reduce = 99%, Cumulative CPU 11.04 sec 2018-10-08 03:52:36,808 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 14.57 sec MapReduce Total cumulative CPU time: 14 seconds 570 msec Ended Job = job_1538648439686_0006 Loading data to table default.hivetest1 Table default.hivetest1 stats: [numFiles=3, numRows=5, totalSize=1707, rawDataSize=0] MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 3 Cumulative CPU: 14.57 sec HDFS Read: 14448 HDFS Write: 1908 SUCCESS Total MapReduce CPU Time Spent: 14 seconds 570 msec OK Time taken: 119.75 seconds hive> select * from HiveTest1; OK 5 akjs moi 4 john noida 3 amit noida 2 ashu1 ggn 1 ashu delhi Time taken: 0.259 seconds, Fetched: 5 row(s)
 And you’re done. Now you can easily perform whatever update and delete operations you want to perform.
And you’re done. Now you can easily perform whatever update and delete operations you want to perform.
Update Hive Table
Now let’s say we want to update the above Hive table, we can simply write the command like below-
hive> update HiveTest1 set name='ashish' where id=5;
This will run the complete MapReduce job and you will get the job done as shown below-
 Insert into Hive Table
Insert into Hive Table
You can insert a new record also into a hive table as below-
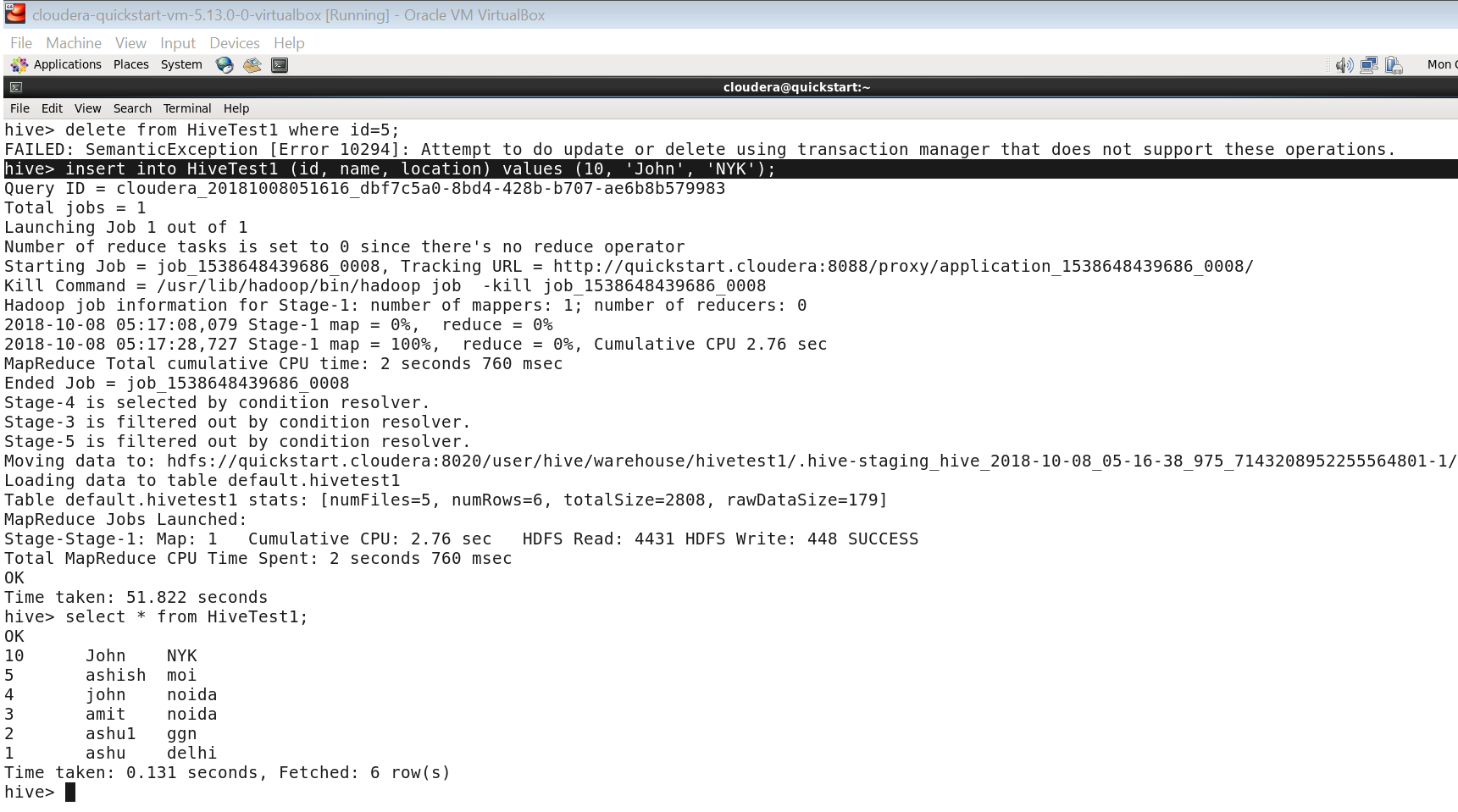
hive> insert into HiveTest1 (id, name, location) values (10, 'John', 'NYK');
Delete operation on Hive table
Similarly, you can perform the delete operation on hive table like below-
hive> delete from HiveTest1 where id=5;
Conclusion
These were the ways using which you can perform CRUD operations in Hive. Although update and delete operations in Hive is not much preferred as Hive is majorly meant for the batch operations. But if you still need, you can do so.
Do try this update and delete operations on Hive table and let me know if you will find any problem doing it.


Excellent tutorial Thank you and keep on update latest changes or any challanges.
niceeeeeee